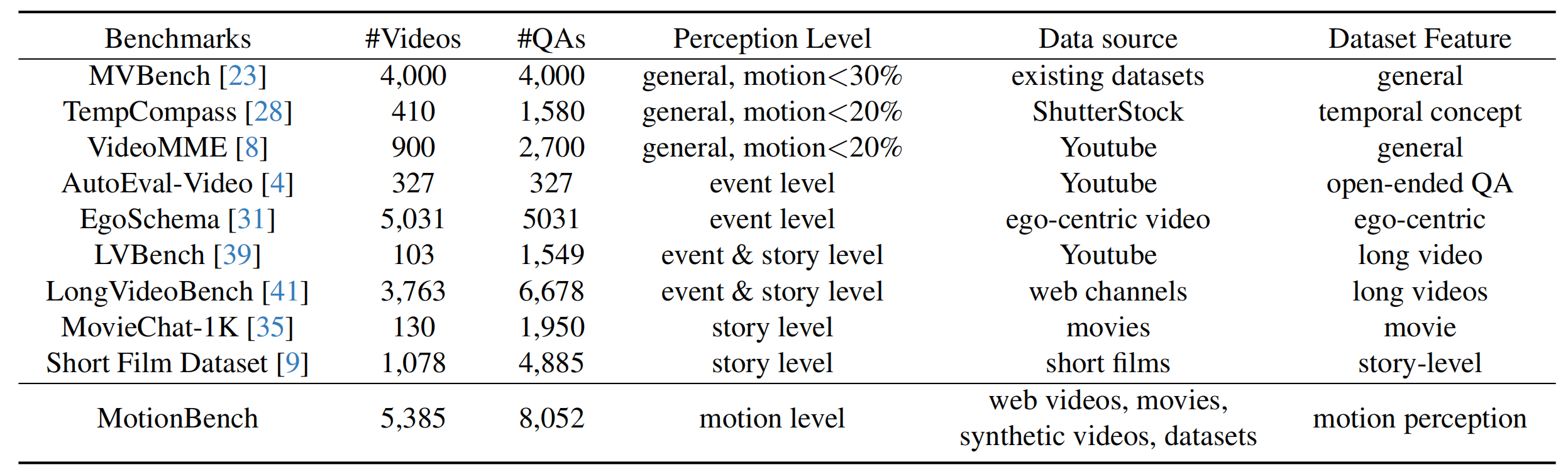
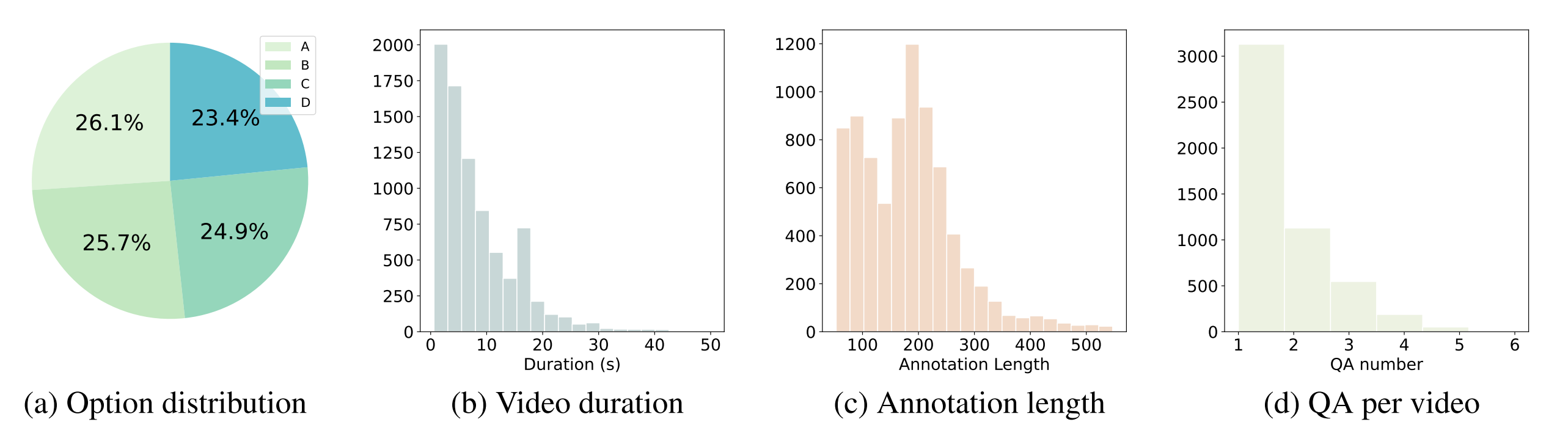
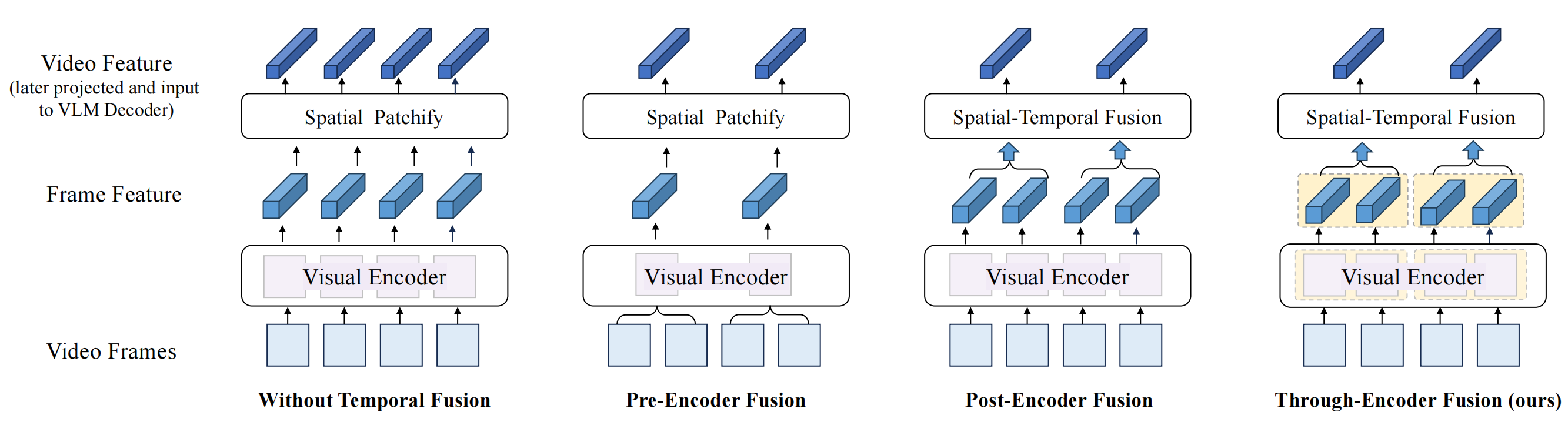
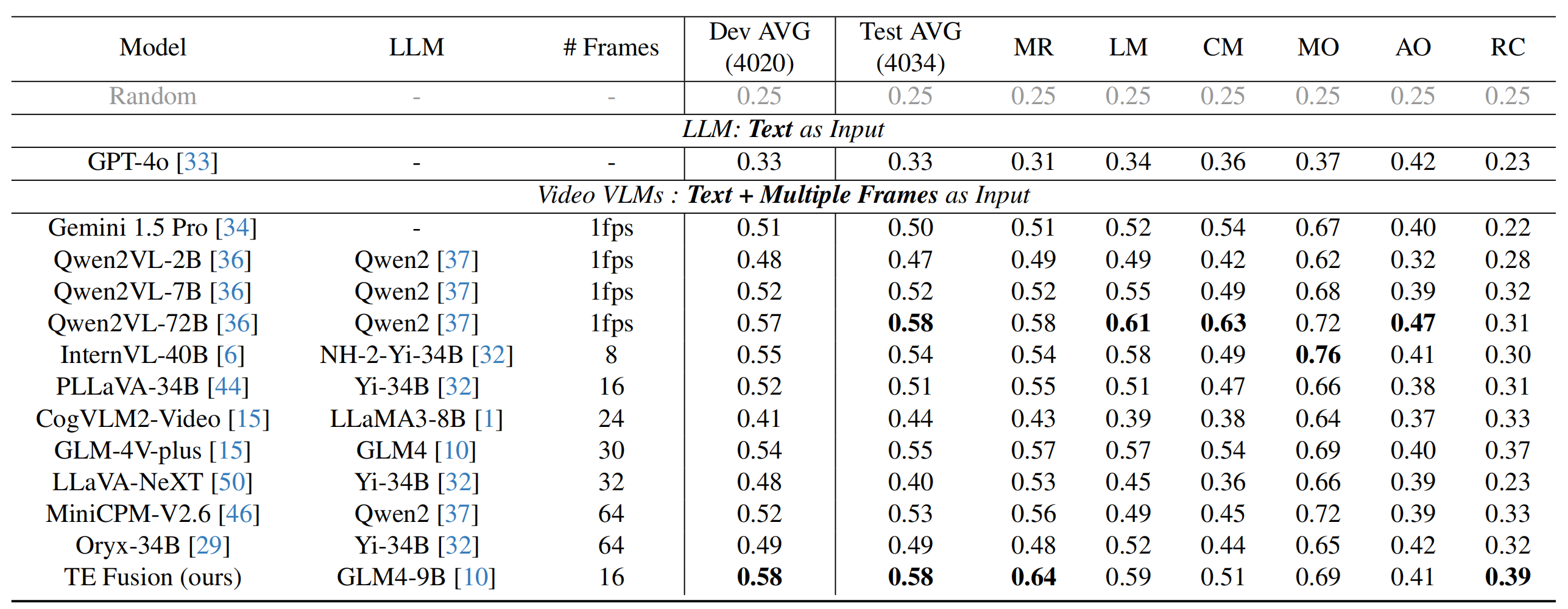
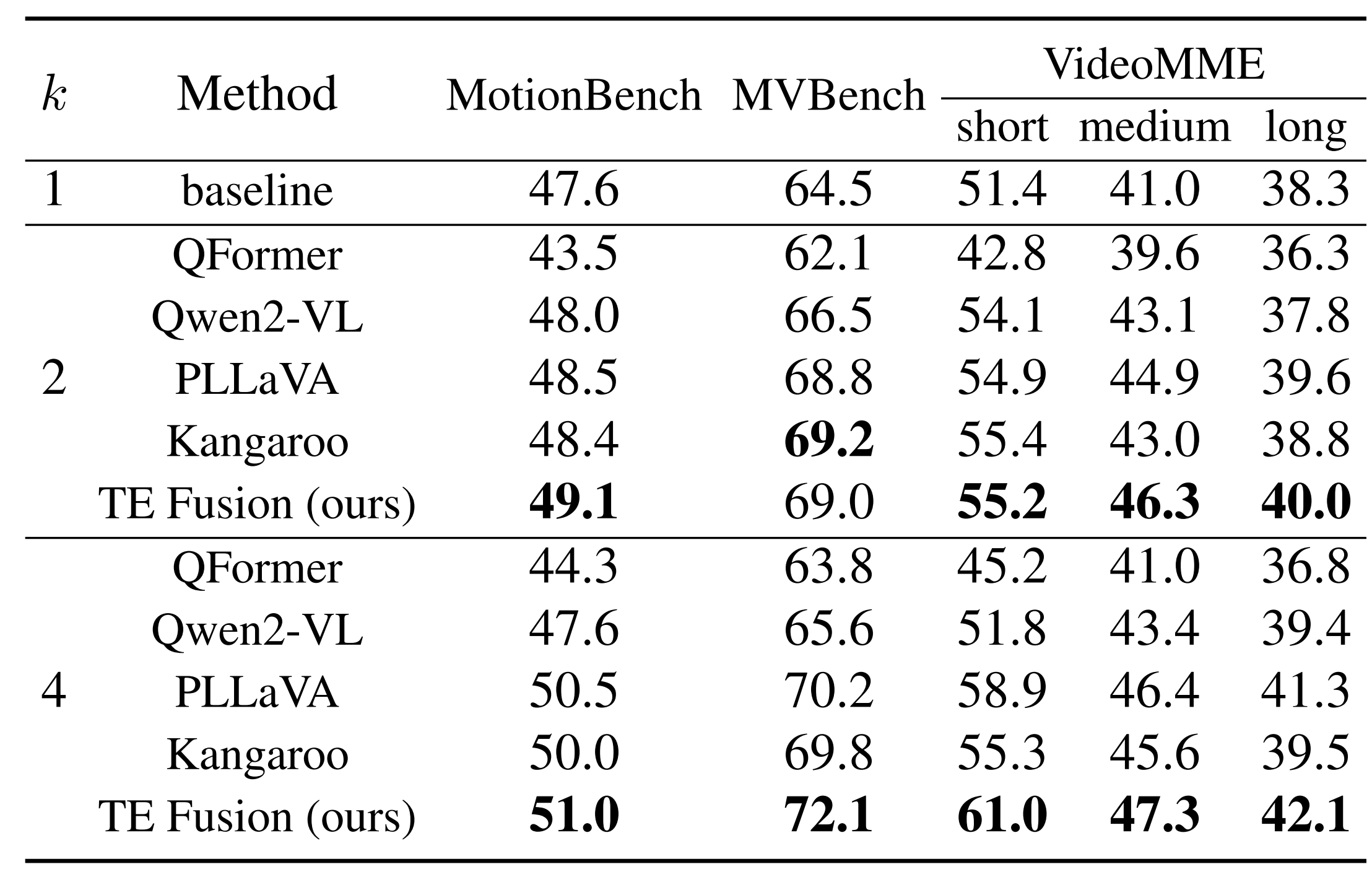
Accuracy scores on MotionBench.
| # | Model | Frames | LLM Params |
Date | Dev Avg (%) | Test Avg (%) | MR (%) | LM (%) | CM (%) | MO (%) | AO (%) | RC (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini-3-Pro-Preview
|
- | - | 2025-12-5 | 69.9 | 70.4 | 70.9 | 73.9 | 66.7 | 83.4 | 55.0 | 61.2 | |
| Gemini-2.5-Pro
|
- | - | 2025-3-25 | 65.8 | 66.3 | 67.0 | 67.5 | 65.6 | 77.5 | 53.9 | 57.0 | |
| GPT-5.1
OpenAI |
- | - | 2025-11-12 | 66.2 | 66.2 | 69.6 | 68.8 | 53.6 | 76.6 | 54.6 | 56.7 | |
| Claude-Opus-4.5
Anthropic |
- | - | 2025-11-25 | - | 65.9 | 66.5 | 71.0 | 71.0 | 79.7 | 55.0 | 36.9 | |
| GLM-4.5V
Z.ai |
2fps | 106B(A12B) | 2025-8-27 | 61.42 | 62.39 | 65.08 | 65.16 | 58.72 | 77.38 | 48.34 | 40.37 | |
| Claude-Sonnet-4.5
Anthropic |
- | - | 2025-9-30 | - | 61.1 | 63.2 | 66.5 | 59.2 | 74.3 | 54.4 | 29.4 | |
| Seed1.5-VL
ByteDance |
2fps | - | 2025-8-27 | 58.81 | 59.44 | 61.37 | 66.67 | 58.61 | 73.79 | 49.38 | 26.74 | |
| gpt-5-chat
OpenAI |
2fps | - | 2025-8-27 | 58.81 | 59.44 | 61.37 | 66.67 | 58.61 | 73.79 | 49.38 | 26.74 | |
| GLM-4.1V-Thinking
Z.ai |
2fps | 9B | 2025-8-27 | 58.68 | 59.44 | 62.48 | 62.98 | 53.85 | 76.18 | 46.23 | 33.51 | |
| gemini-2.5-flash
|
2fps | - | 2025-8-27 | 56.12 | 57.21 | 59.25 | 59.97 | 59.9 | 72.55 | 44.4 | 29.14 | |
| Qwen2.5-VL-72B
Alibaba |
64 | 72B | 2025-8-27 | 56.14 | 56.1 | 59.48 | 58.96 | 47.95 | 72.89 | 45.53 | 28.73 | |
| Kimi-VL-2506
Kimi |
2fps | 16B (A3B) | 2025-8-27 | 54.6 | 54.26 | 58.7 | 55.78 | 45.64 | 73.48 | 42.08 | 22.52 | |
| GLM-4V-Plus-0111
Z.ai |
2fps | - | 2025-1-29 | 62.8 | 62.5 | 64.1 | 67 | 67.4 | 73.5 | 46.7 | 42.8 | |
| InternVL2.5-78B
Shanghai AI Lab |
16 | 72B | 2025-1-24 | 60.9 | 61 | 65.2 | 64.6 | 55.6 | 75.7 | 46.9 | 33.7 | |
| TE Fusion
Z.ai & Tsinghua |
16 | 9B | 2024-11-25 | 58 | 58 | 64 | 59 | 51 | 69 | 41 | 39 | |
| Qwen2-VL-72B
Alibaba |
1fps | 72B | 2024-11-25 | 57 | 58 | 58 | 61 | 63 | 72 | 47 | 31 | |
| InternVL2-40B
Shanghai AI Lab |
16 | 34B | 2024-11-25 | 55 | 54 | 54 | 58 | 49 | 76 | 41 | 30 | |
| GLM-4V-Plus
Z.ai |
30 | - | 2024-11-25 | 54 | 55 | 57 | 57 | 54 | 69 | 40 | 37 | |
| MiniCPM-V2.6
Tsinghua |
64 | 7B | 2024-11-25 | 52 | 53 | 56 | 49 | 45 | 72 | 39 | 33 | |
| PLLaVA 34B
Bytedance & NTU |
16 | 34B | 2024-11-25 | 52 | 51 | 55 | 51 | 47 | 66 | 38 | 31 | |
| Gemini 1.5 Pro
|
1fps | - | 2024-11-25 | 51 | 50 | 51 | 52 | 54 | 67 | 40 | 22 | |
| Oryx-34B
Tsinghua University & Tencent & NTU |
64 | 34B | 2024-11-25 | 49 | 49 | 48 | 52 | 44 | 65 | 42 | 32 | |
| LLaVA-NeXT-Video-DPO (34B)
Bytedance & NTU S-Lab |
32 | 34B | 2024-11-25 | 48 | 40 | 53 | 45 | 36 | 66 | 39 | 23 | |
| CogVLM2-Video
Z.ai |
24 | 8B | 2024-11-25 | 41 | 44 | 43 | 39 | 38 | 64 | 37 | 33 |
Green date indicates the newly added/updated models.